kudu
KuDu
一概述
背景介绍
在KUDU之前,大数据主要以两种方式存储;
(1)静态数据:
以 HDFS 引擎作为存储引擎,适用于高吞吐量的离线大数据分析场景。
这类存储的局限性是数据无法进行随机的读写。
(2)动态数据:
以 HBase、Cassandra 作为存储引擎,适用于大数据随机读写场景。
局限性是批量读取吞吐量远不如 HDFS,不适用于批量数据分析的场景。
从上面分析可知,这两种数据在存储方式上完全不同,进而导致使用场景完全不同,但在真实的场景中,边界可能没有那么清晰,面对既需要随机读写,又需要批量分析的大数据场景,该如何选择呢?
这个场景中,单种存储引擎无法满足业务需求,我们需要通过多种大数据工具组合来满足这一需求
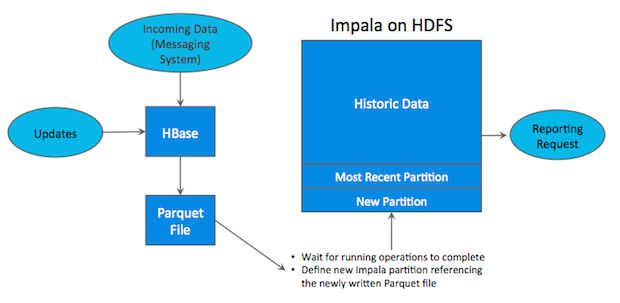
如上图所示,数据实时写入 HBase,实时的数据更新也在 HBase 完成,为了应对 OLAP 需求,我们定时将 HBase 数据写成静态的文件(如:Parquet)导入到 OLAP 引擎(如:Impala、hive)。这一架构能满足既需要随机读写,又可以支持 OLAP 分析的场景,但他有如下缺点:
(1)架构复杂。从架构上看,数据在HBase、消息队列、HDFS 间流转,涉及环节太多,运维成本很高。并且每个环节需要保证高可用,都需要维护多个副本,存储空间也有一定的浪费。最后数据在多个系统上,对数据安全策略、监控等都提出了挑战。
(2)时效性低。数据从HBase导出成静态文件是周期性的,一般这个周期是一天(或一小时),在时效性上不是很高。
(3)难以应对后续的更新。真实场景中,总会有数据是延迟到达的。如果这些数据之前已经从HBase导出到HDFS,新到的变更数据就难以处理了,一个方案是把原有数据应用上新的变更后重写一遍,但这代价又很高。
为了解决上述架构的这些问题,KUDU应运而生。KUDU的定位是Fast Analytics on Fast Data,是一个既支持随机读写、又支持 OLAP 分析的大数据存储引擎。
KUDU 是一个折中的产品,在 HDFS 和 HBase 这两个偏科生中平衡了随机读写和批量分析的性能。从 KUDU 的诞生可以说明一个观点:底层的技术发展很多时候都是上层的业务推动的,脱离业务的技术很可能是空中楼阁。
kudu是什么
- 是一个大数据存储引擎 用于大数据的存储,结合其他软件开展数据分析。
- 汲取了hdfs中高吞吐数据的能力和hbase中高随机读写数据的能力
- 既满足有传统OLAP分析 又满足于随机读写访问数据
- kudu来自于cloudera 后来贡献给了apache
kudu应用场景
适用于那些既有随机访问,也有批量数据扫描的复合场景
高计算量的场景
使用了高性能的存储设备,包括使用更多的内存
支持数据更新,避免数据反复迁移
支持跨地域的实时数据备份和查询
二架构
- kudu集群是主从架构
- 主角色 master :管理集群 管理元数据
- 从角色 tablet server:负责最终数据的存储 对外提供数据读写能力 里面存储的都是一个个tablet
- kudu tablet
- 是kudu表中的数据水平分区 一个表可以划分成为多个tablet(类似于hbase region)
- tablet中主键是不重复连续的 所有tablet加起来就是一个table的所有数据
- tablet在存储的时候 会进行冗余存放 设置多个副本
- 在一个tablet所有冗余中 任意时刻 一个是leader 其他的冗余都是follower
与HDFS和HBase相似,Kudu使用单个的Master节点,用来管理集群的元数据,并且使用任意数量的Tablet Server(类似HBase中的RegionServer角色)节点用来存储实际数据。可以部署多个Master节点来提高容错性。
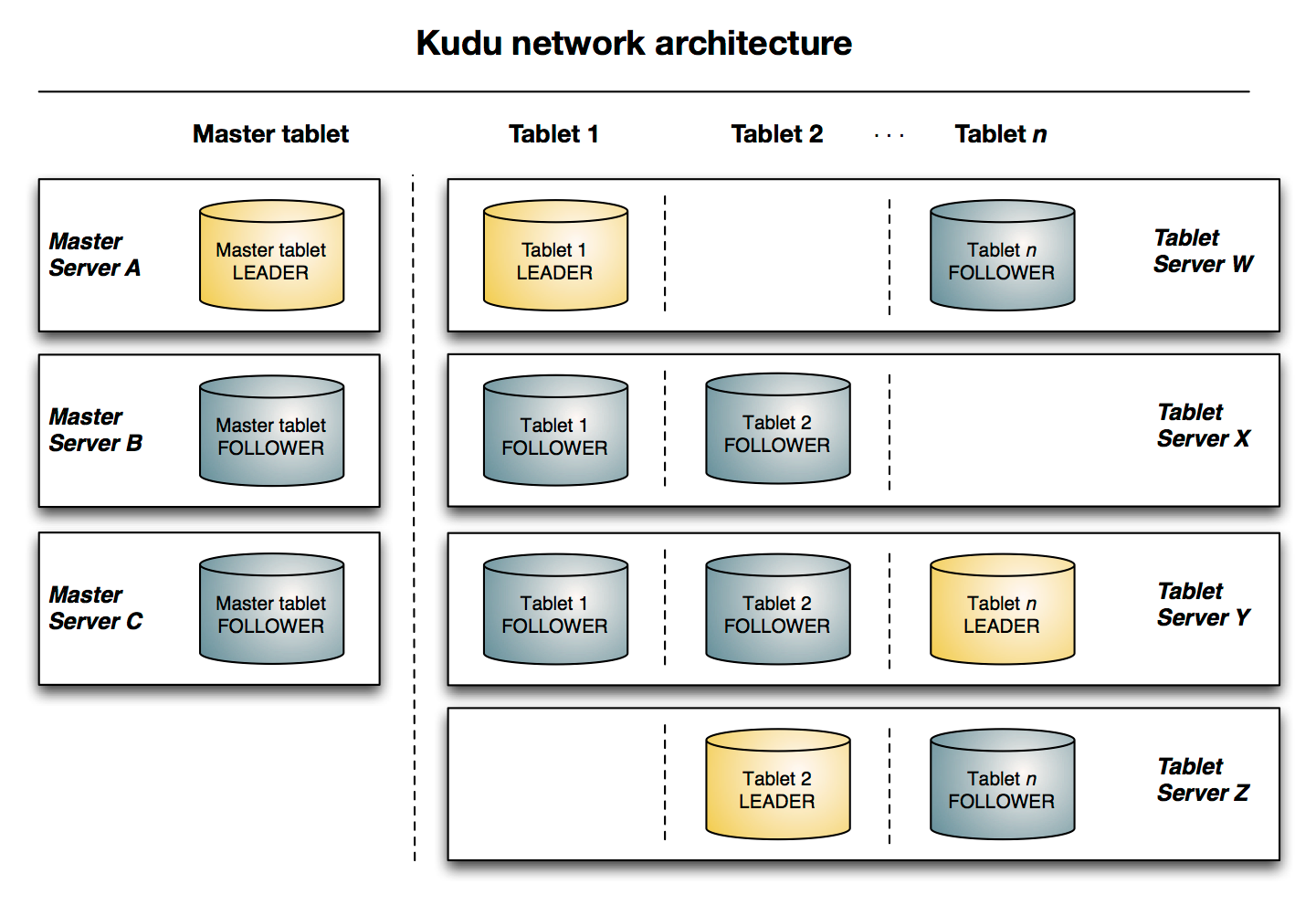
1. Table
表(Table)是数据库中用来存储数据的对象,是有结构的数据集合。kudu中的表具有schema(纲要)和全局有序的primary key(主键)。kudu中一个table会被水平分成多个被称之为tablet的片段。
2. Tablet
一个 tablet 是一张 table连续的片段,tablet是kudu表的水平分区,类似于HBase的region。每个tablet存储着一定连续range的数据(key),且tablet两两间的range不会重叠。一张表的所有tablet包含了这张表的所有key空间。
tablet 会冗余存储。放置到多个 tablet server上,并且在任何给定的时间点,其中一个副本被认为是leader tablet,其余的被认之为follower tablet。每个tablet都可以进行数据的读请求,但只有Leader tablet负责写数据请求。
3. Tablet Server
tablet server集群中的小弟,负责数据存储,并提供数据读写服务
一个 tablet server 存储了table表的tablet,向kudu client 提供读取数据服务。对于给定的 tablet,一个tablet server 充当 leader,其他 tablet server 充当该 tablet 的 follower 副本。
只有 leader服务写请求,然而 leader 或 followers 为每个服务提供读请求 。一个 tablet server 可以服务多个 tablets ,并且一个 tablet 可以被多个 tablet servers 服务着。
4. Master Server
集群中的老大,负责集群管理、元数据管理等功能。
三 kudu安装
1节点规划
| 节点 | kudu-master | kudu-tserver |
|---|---|---|
| node01 | 是 | 是 |
| node02 | 是 | 是 |
| node03 | 是 | 是 |
本次配置node01 和node02 不配置 kudu-master
2本地yum源配置
配过了在 node03上
3 安装KUDU
| 服务器 | 安装命令 |
|---|---|
| node01 | yum install -y kudu kudu-tserver kudu-client0 kudu-client-devel |
| node02 | yum install -y kudu kudu-tserver kudu-client0 kudu-client-devel |
| node03 | yum install -y kudu kudu-master kudu-tserver kudu-client0 kudu-client-devel |
1 | yum install kudu # Kudu的基本包 |
4 kudu节点配置
安装完成之后。 需要在所有节点的/etc/kudu/conf目录下有两个文件:master.gflagfile和tserver.gflagfile。
1.1. 修改master.gflagfile
1 | # cat /etc/kudu/conf/master.gflagfile |
1.2 修改tserver.gflagfile
1 | # Do not modify these two lines. If you wish to change these variables, |
1.3修改 /etc/default/kudu-master
1 | export FLAGS_log_dir=/var/log/kudu |
1.4修改 /etc/default/kudu-tserver
1 | export FLAGS_log_dir=/var/log/kudu |
kudu默认用户就是KUDU,所以需要将/export/servers/kudu权限修改成kudu:
1 | mkdir /export/servers/kudu |
(如果使用的是普通的用户,那么最好配置sudo权限)/etc/sudoers文件中添加:
kudu集群的启动与关闭
1 ntp服务的安装
启动的时候要注意时间同步
安装ntp服务
1 | yum -y install ntp |
设置开机启动
1 | service ntpd start |
可以在每台服务器执行
1 | /etc/init.d/ntpd restart |
安装属于事项
1.1给普通用户授予sudo出错
1 | sudo: /etc/sudoers is world writable |
1.2 启动kudu的时候报错
1 | Failed to start Kudu Master Server. Return value: 1 [FAILED] |
1.3 启动过程中报错
1 | Invalid argument: Unable to initialize catalog manager: Failed to initialize sys |
1.4 启动过程中报错
1 | error: Could not create new FS layout: unable to create file system roots: unable to |
四 Java操作kudu
###1 创建maven工程 导入依赖
1 | <dependencies> |
2 初始化方法
1 | public class TestKudu { |
3 创建表
1 | /** |
4 插入数据
1 | /** |
5 查询数据
1 | /** |
6 修改数据
1 | /** |
7删除数据
1 | /** |
8 删除表
1 | @Test |
9 kudu的分区方式
为了提供可扩展性,Kudu 表被划分为称为 tablet 的单元,并分布在许多 tablet servers 上。行总是属于单个tablet 。将行分配给 tablet 的方法由在表创建期间设置的表的分区决定。 kudu提供了3种分区方式。
1 范围分区Range Partitioning
范围分区可以根据存入数据的数据量,均衡的存储到各个机器上,防止机器出现负载不均衡现象.
1 | /** |
2 哈希分区Hash Partitioning 为kudu的默认分区
哈希分区通过哈希值将行分配到许多 buckets (存储桶 )之一; 哈希分区是一种有效的策略,当不需要对表进行有序访问时。哈希分区对于在 tablet 之间随机散布这些功能是有效的,这有助于减轻热点和 tablet 大小不均匀。
1 | /** |
3 多级分区Multilevel Partitioning
Kudu 允许一个表在单个表上组合多级分区。 当正确使用时,多级分区可以保留各个分区类型的优点,同时减少每个分区的缺点
如 范围分区 为5个 hash分区为3个 则多级分区为15个 (即在范围分区里面有进行了hash分区)
1 | /** |
五 kudu集成impala
1 impala的配置修改
可选项 若配置以后写的时候指定 master地址即可
在每一个服务器的impala的配置文件中添加如下配置。
1 | vim /etc/default/impala |
在IMPALA_SERVER_ARGS`下添加:
1 |
-kudu_master_hosts=node-1:7051,node-2:7051,node-3:7051
1 | ### 2 创建kudu表 |
INSERT INTO my_first_table VALUES (50, “zhangsan”);
1 | 此示例插入3行: |
INSERT INTO my_first_table VALUES (1, “john”), (2, “jane”), (3, “jim”);
1 | 批量导入数据: |
INSERT INTO my_first_table SELECT * FROM temp1;
1 | 2 更新数据 |
UPDATE my_first_table SET name=”xiaowang” where id =1 ;
1 | 3 删除数据 |
delete from my_first_table where id =2;
1 | 4 更改表属性 |
ALTER TABLE PERSON RENAME TO person_temp;
1 | 4.2重新命名内部表的基础kudu表 |
ALTER TABLE kudu_student SET TBLPROPERTIES(‘kudu.table_name’ = ‘new_student’);
<!–33–>
CREATE EXTERNAL TABLE external_table
STORED AS KUDU
TBLPROPERTIES (
‘kudu.master_addresses’ = ‘node1:7051,node2:7051,node3:7051’,
‘kudu.table_name’ = ‘person’
);
1 |
|
ALTER TABLE external_table
SET TBLPROPERTIES(‘kudu.table_name’ = ‘hashTable’)
1 |
|
ALTER TABLE my_table
SET TBLPROPERTIES(‘kudu.master_addresses’ = ‘kudu-new-master.example.com:7051’);
1 |
|
ALTER TABLE my_table SET TBLPROPERTIES(‘EXTERNAL’ = ‘TRUE’);
1 |
|
<!--Caused by : ClassNotFound : thrift.protocol.TPro-->
<dependency>
<groupId>org.apache.thrift</groupId>
<artifactId>libfb303</artifactId>
<version>0.9.3</version>
<type>pom</type>
</dependency>
<!--Caused by : ClassNotFound : thrift.protocol.TPro-->
<dependency>
<groupId>org.apache.thrift</groupId>
<artifactId>libthrift</artifactId>
<version>0.9.3</version>
<type>pom</type>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<exclusions>
<exclusion>
<groupId>org.apache.hive</groupId>
<artifactId>hive-service-rpc</artifactId>
</exclusion>
<exclusion>
<groupId>org.apache.hive</groupId>
<artifactId>hive-service</artifactId>
</exclusion>
</exclusions>
<version>1.1.0</version>
</dependency>
<!--导入hive-->
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-service</artifactId>
<version>1.1.0</version>
</dependency>1 |
|
package cn.itcast.impala.impala;
public class Person {
private int companyId;
private int workId;
private String name;
private String gender;
private String photo;
public Person(int companyId, int workId, String name, String gender, String photo) {
this.companyId = companyId;
this.workId = workId;
this.name = name;
this.gender = gender;
this.photo = photo;
}
public int getCompanyId() {
return companyId;
}
public void setCompanyId(int companyId) {
this.companyId = companyId;
}
public int getWorkId() {
return workId;
}
public void setWorkId(int workId) {
this.workId = workId;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getGender() {
return gender;
}
public void setGender(String gender) {
this.gender = gender;
}
public String getPhoto() {
return photo;
}
public void setPhoto(String photo) {
this.photo = photo;
}}
1 |
|
package cn.itcast.impala.impala;
import java.sql.*;
public class Contants {
private static String JDBC_DRIVER=”com.cloudera.impala.jdbc41.Driver”;
private static String CONNECTION_URL=”jdbc:impala://node1:21050/default;auth=noSasl”;
//定义数据库连接
static Connection conn=null;
//定义PreparedStatement对象
static PreparedStatement ps=null;
//定义查询的结果集
static ResultSet rs= null;
//数据库连接
public static Connection getConn(){
try {
Class.forName(JDBC_DRIVER);
conn=DriverManager.getConnection(CONNECTION_URL);
} catch (Exception e) {
e.printStackTrace();
}
return conn;
}
//创建一个表
public static void createTable(){
conn=getConn();
String sql="CREATE TABLE impala_kudu_test" +
"(" +
"companyId BIGINT," +
"workId BIGINT," +
"name STRING," +
"gender STRING," +
"photo STRING," +
"PRIMARY KEY(companyId)" +
")" +
"PARTITION BY HASH PARTITIONS 16 " +
"STORED AS KUDU " +
"TBLPROPERTIES (" +
"'kudu.master_addresses' = 'node1:7051,node2:7051,node3:7051'," +
"'kudu.table_name' = 'impala_kudu_test'" +
");";
try {
ps = conn.prepareStatement(sql);
ps.execute();
} catch (SQLException e) {
e.printStackTrace();
}
}
//查询数据
public static ResultSet queryRows(){
try {
//定义执行的sql语句
String sql="select * from impala_kudu_test";
ps = getConn().prepareStatement(sql);
rs= ps.executeQuery();
} catch (SQLException e) {
e.printStackTrace();
}
return rs;
}
//打印结果
public static void printRows(ResultSet rs){
/**
private int companyId;
private int workId;
private String name;
private String gender;
private String photo;
*/
try {
while (rs.next()){
//获取表的每一行字段信息
int companyId = rs.getInt("companyId");
int workId = rs.getInt("workId");
String name = rs.getString("name");
String gender = rs.getString("gender");
String photo = rs.getString("photo");
System.out.print("companyId:"+companyId+" ");
System.out.print("workId:"+workId+" ");
System.out.print("name:"+name+" ");
System.out.print("gender:"+gender+" ");
System.out.println("photo:"+photo);
}
} catch (SQLException e) {
e.printStackTrace();
}finally {
if(ps!=null){
try {
ps.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if(conn !=null){
try {
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}
//插入数据
public static void insertRows(Person person){
conn=getConn();
String sql="insert into table impala_kudu_test(companyId,workId,name,gender,photo) values(?,?,?,?,?)";
try {
ps=conn.prepareStatement(sql);
//给占位符?赋值
ps.setInt(1,person.getCompanyId());
ps.setInt(2,person.getWorkId());
ps.setString(3,person.getName());
ps.setString(4,person.getGender());
ps.setString(5,person.getPhoto());
ps.execute();
} catch (SQLException e) {
e.printStackTrace();
}finally {
if(ps !=null){
try {
//关闭
ps.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if(conn !=null){
try {
//关闭
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}
//更新数据
public static void updateRows(Person person){
//定义执行的sql语句
String sql="update impala_kudu_test set workId="+person.getWorkId()+
",name='"+person.getName()+"' ,"+"gender='"+person.getGender()+"' ,"+
"photo='"+person.getPhoto()+"' where companyId="+person.getCompanyId();
try {
ps= getConn().prepareStatement(sql);
ps.execute();
} catch (SQLException e) {
e.printStackTrace();
}finally {
if(ps !=null){
try {
//关闭
ps.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if(conn !=null){
try {
//关闭
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}
//删除数据
public static void deleteRows(int companyId){
//定义sql语句
String sql="delete from impala_kudu_test where companyId="+companyId;
try {
ps =getConn().prepareStatement(sql);
ps.execute();
} catch (SQLException e) {
e.printStackTrace();
}
} //删除表
public static void dropTable() {
String sql=”drop table if exists impala_kudu_test”;
try {
ps =getConn().prepareStatement(sql);
ps.execute();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
1 |
|
package cn.itcast.impala.impala;
import java.sql.Connection;
public class ImpalaJdbcClient {
public static void main(String[] args) {
Connection conn = Contants.getConn();
//创建一个表
Contants.createTable();
//插入数据
Contants.insertRows(new Person(1,100,"lisi","male","lisi-photo"));
//查询表的数据
ResultSet rs = Contants.queryRows();
Contants.printRows(rs);
//更新数据
Contants.updateRows(new Person(1,200,"zhangsan","male","zhangsan-photo"));
//删除数据
Contants.deleteRows(1);
//删除表
Contants.dropTable();
}}
```
六 Apache KUDU的原理
1. table与schema
Kudu设计是面向结构化存储的,因此,Kudu的表需要用户在建表时定义它的Schema信息,这些Schema信息包含:列定义(含类型),Primary Key定义(用户指定的若干个列的有序组合)。数据的唯一性,依赖于用户所提供的Primary Key中的Column组合的值的唯一性。Kudu提供了Alter命令来增删列,但位于Primary Key中的列是不允许删除的。
从用户角度来看,Kudu是一种存储结构化数据表的存储系统。在一个Kudu集群中可以定义任意数量的table,每个table都需要预先定义好schema。每个table的列数是确定的,每一列都需要有名字和类型,每个表中可以把其中一列或多列定义为主键。这么看来,Kudu更像关系型数据库,而不是像HBase、Cassandra和MongoDB这些NoSQL数据库。不过Kudu目前还不能像关系型数据一样支持二级索引。
Kudu使用确定的列类型,而不是类似于NoSQL的“everything is byte”。带来好处:确定的列类型使Kudu可以进行类型特有的编码,可以提供元数据给其他上层查询工具。
2 kudu底层数据模型
Kudu的底层数据文件的存储,未采用HDFS这样的较高抽象层次的分布式文件系统,而是自行开发了一套可基于Table/Tablet/Replica视图级别的底层存储系统。
这套实现基于如下的几个设计目标:
• 可提供快速的列式查询
• 可支持快速的随机更新
• 可提供更为稳定的查询性能保障
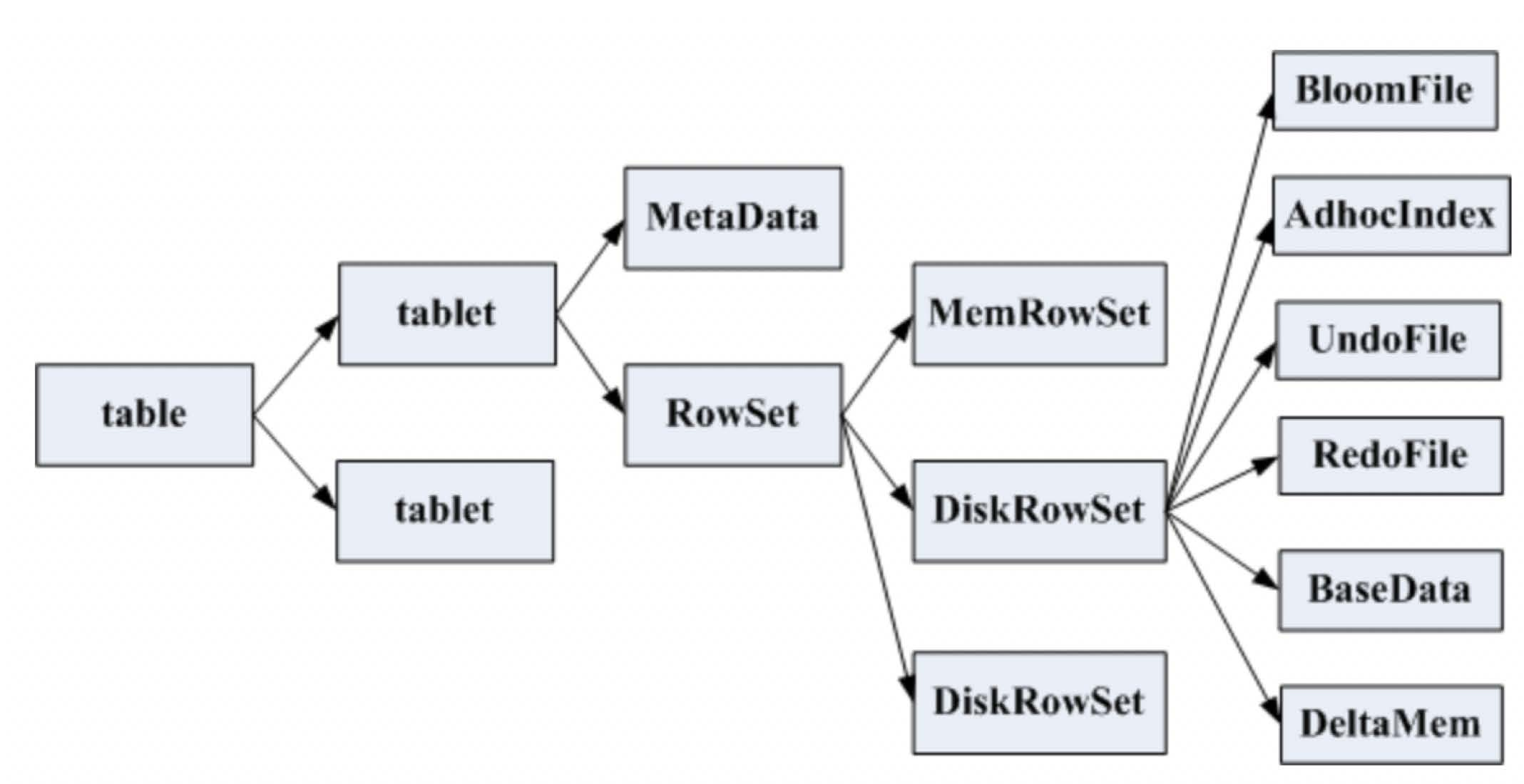
一张table会分成若干个tablet,每个tablet包括MetaData元信息及若干个RowSet。
RowSet包含一个MemRowSet及若干个DiskRowSet,DiskRowSet中包含一个BloomFile、Ad_hoc Index、BaseData、DeltaMem及若干个RedoFile和UndoFile。
MemRowSet:用于新数据insert及已在MemRowSet中的数据的更新,一个MemRowSet写满后会将数据刷到磁盘形成若干个DiskRowSet。默认是1G或者或者120S。
DiskRowSet:用于老数据的变更,后台定期对DiskRowSet做compaction,以删除没用的数据及合并历史数据,减少查询过程中的IO开销。
BloomFile:根据一个DiskRowSet中的key生成一个bloom filter,用于快速模糊定位某个key是否在DiskRowSet中。
Ad_hocIndex:是主键的索引,用于定位key在DiskRowSet中的具体哪个偏移位置。
BaseData是MemRowSet flush下来的数据,按列存储,按主键有序。
UndoFile是基于BaseData之前时间的历史数据,通过在BaseData上apply UndoFile中的记录,可以获得历史数据。
RedoFile是基于BaseData之后时间的变更记录,通过在BaseData上apply RedoFile中的记录,可获得较新的数据。
DeltaMem用于DiskRowSet中数据的变更,先写到内存中,写满后flush到磁盘形成RedoFile。
REDO与UNDO与关系型数据库中的REDO与UNDO日志类似(在关系型数据库中,REDO日志记录了更新后的数据,可以用来恢复尚未写入Data File的已成功事务更新的数据。而UNDO日志用来记录事务更新之前的数据,可以用来在事务失败时进行回滚)
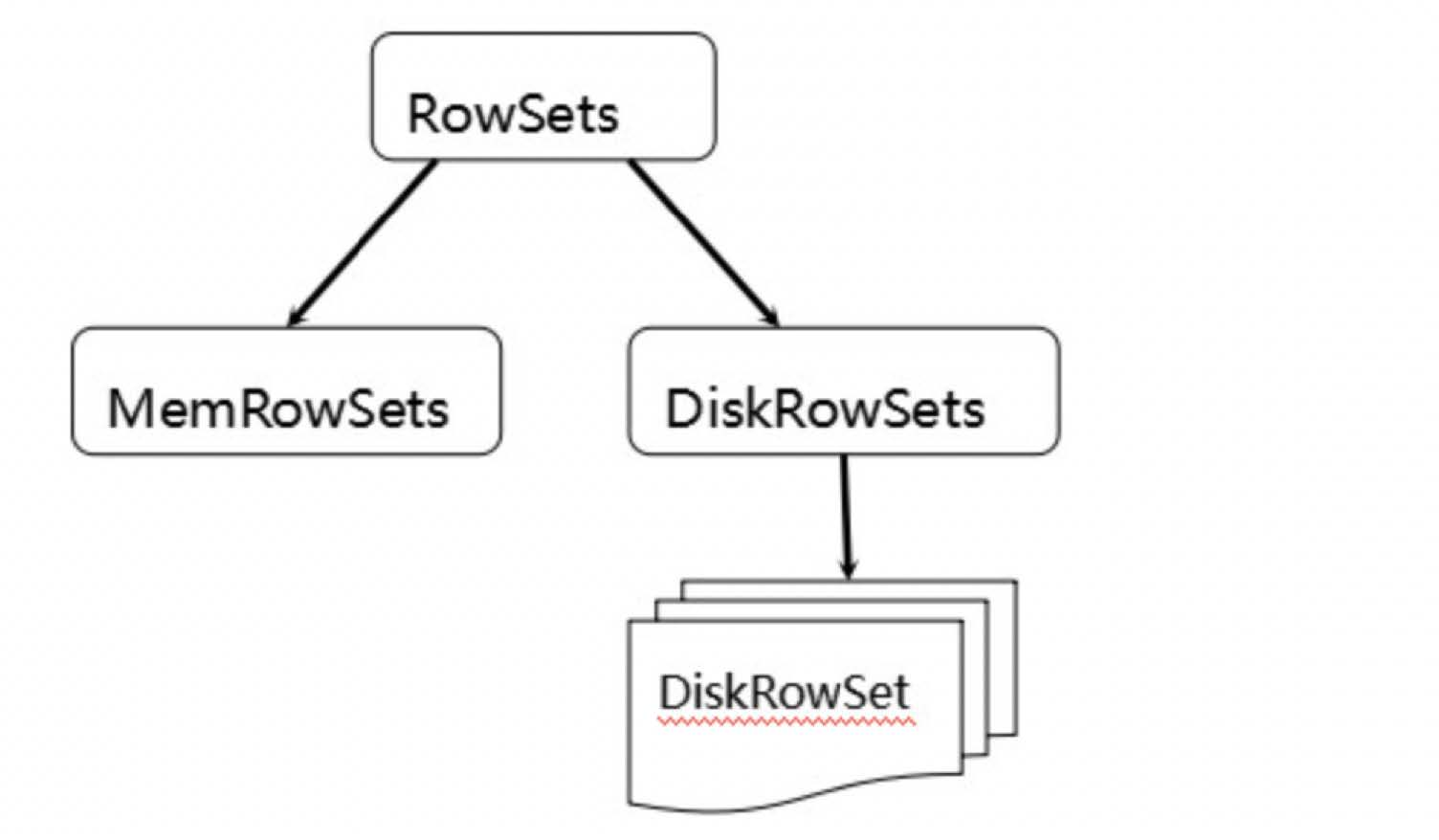
MemRowSets可以对比理解成HBase中的MemStore, 而DiskRowSets可理解成HBase中的HFile。
MemRowSets中的数据被Flush到磁盘之后,形成DiskRowSets。 DisRowSets中的数据,按照32MB大小为单位,按序划分为一个个的DiskRowSet。 DiskRowSet中的数据按照Column进行组织,与Parquet类似。
这是Kudu可支持一些分析性查询的基础。每一个Column的数据被存储在一个相邻的数据区域,而这个数据区域进一步被细分成一个个的小的Page单元,与HBase File中的Block类似,对每一个Column Page可采用一些Encoding算法,以及一些通用的Compression算法。 既然可对Column Page可采用Encoding以及Compression算法,那么,对单条记录的更改就会比较困难了。
前面提到了Kudu可支持单条记录级别的更新/删除,是如何做到的?
与HBase类似,也是通过增加一条新的记录来描述这次更新/删除操作的。DiskRowSet是不可修改了,那么 KUDU 要如何应对数据的更新呢?在KUDU中,把DiskRowSet分为了两部分:base data、delta stores。base data 负责存储基础数据,delta stores负责存储 base data 中的变更数据.
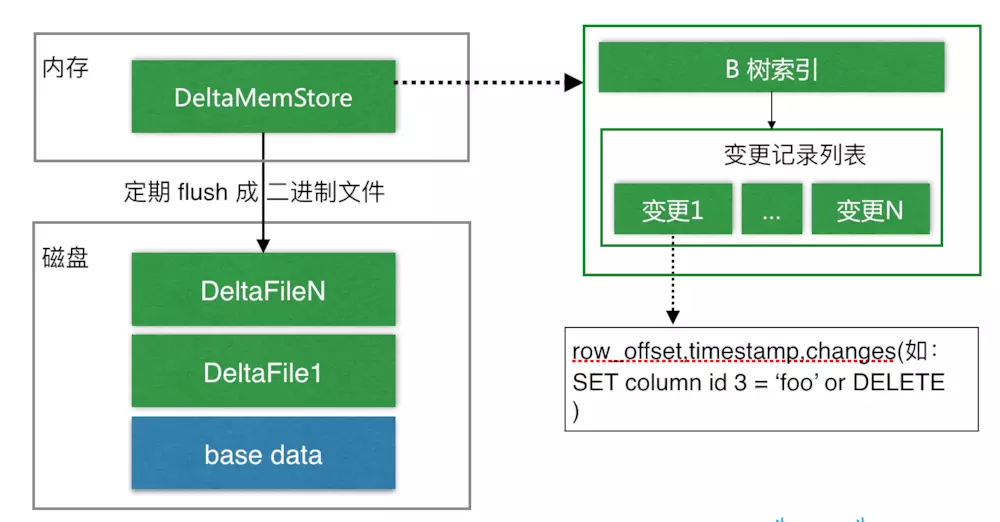
如上图所示,数据从MemRowSet 刷到磁盘后就形成了一份 DiskRowSet(只包含 base data),每份 DiskRowSet 在内存中都会有一个对应的 DeltaMemStore,负责记录此 DiskRowSet 后续的数据变更(更新、删除)。DeltaMemStore 内部维护一个 B-树索引,映射到每个 row_offset 对应的数据变更。DeltaMemStore 数据增长到一定程度后转化成二进制文件存储到磁盘,形成一个 DeltaFile,随着 base data 对应数据的不断变更,DeltaFile 逐渐增长。
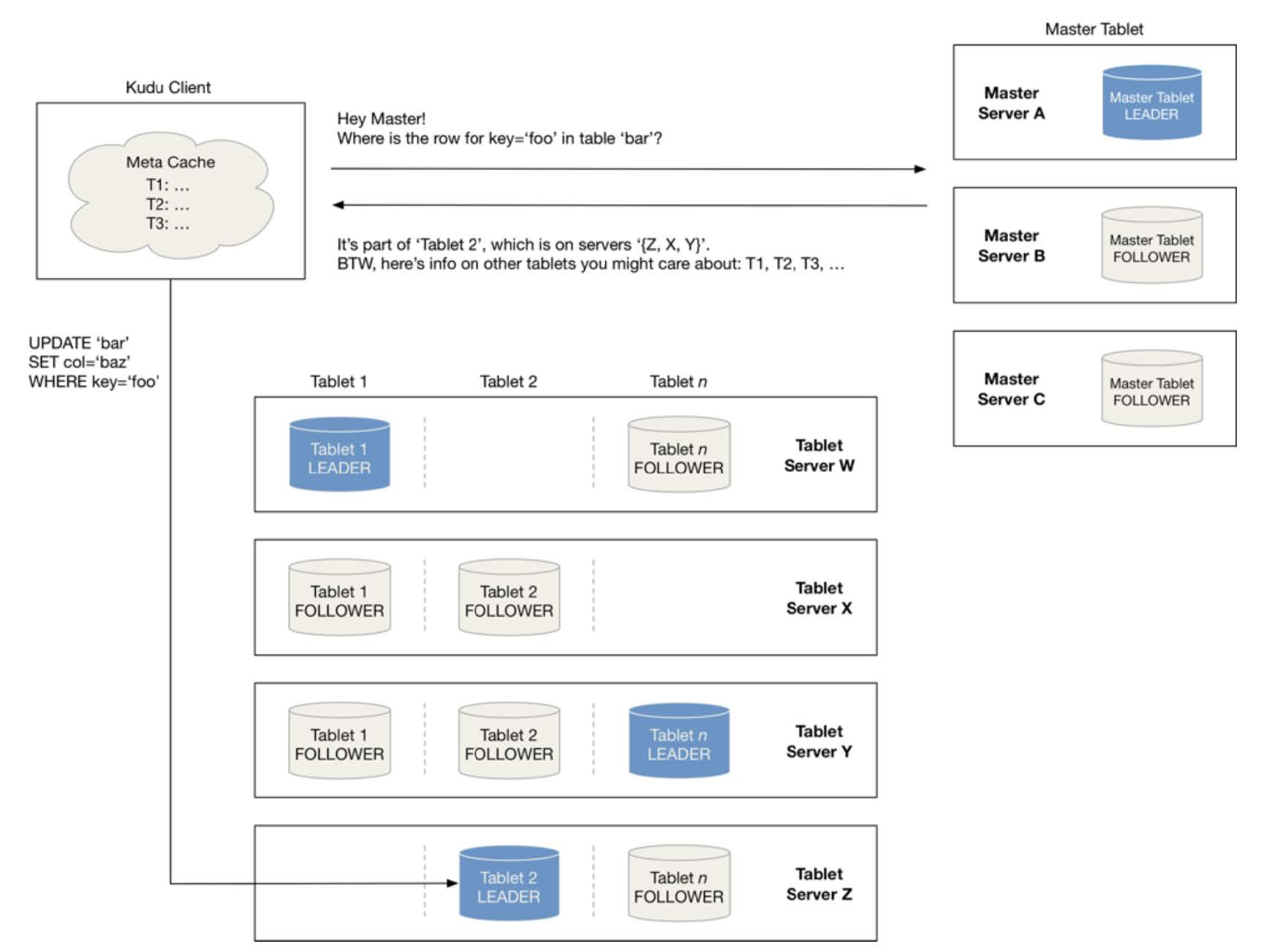
3 tablet发现过程
当创建Kudu客户端时,其会从主服务器上获取tablet位置信息,然后直接与服务于该tablet的服务器进行交谈。
为了优化读取和写入路径,客户端将保留该信息的本地缓存,以防止他们在每个请求时需要查询主机的tablet位置信息。随着时间的推移,客户端的缓存可能会变得过时,并且当写入被发送到不再是tablet领导者的tablet服务器时,则将被拒绝。然后客户端将通过查询主服务器发现新领导者的位置来更新其缓存。
4 kudu写流程
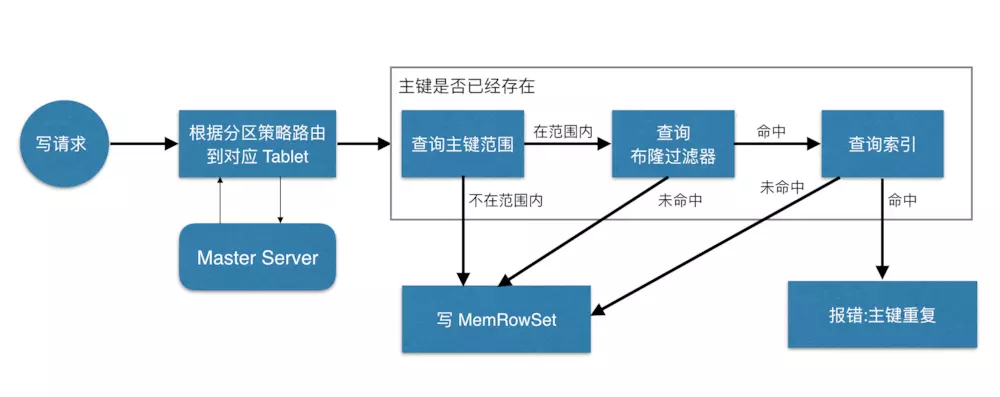
当 Client 请求写数据时,先根据主键从Master Server中获取要访问的目标 Tablets,然后到依次对应的Tablet获取数据。
因为KUDU表存在主键约束,所以需要进行主键是否已经存在的判断,这里就涉及到之前说的索引结构对读写的优化了。一个Tablet中存在很多个RowSets,为了提升性能,我们要尽可能地减少要扫描的RowSets数量。
首先,我们先通过每个 RowSet 中记录的主键的(最大最小)范围,过滤掉一批不存在目标主键的RowSets,然后在根据RowSet中的布隆过滤器,过滤掉确定不存在目标主键的 RowSets,最后再通过RowSets中的 B-树索引,精确定位目标主键是否存在。
如果主键已经存在,则报错(主键重复),否则就进行写数据(写 MemRowSet)。
5kudu读流程
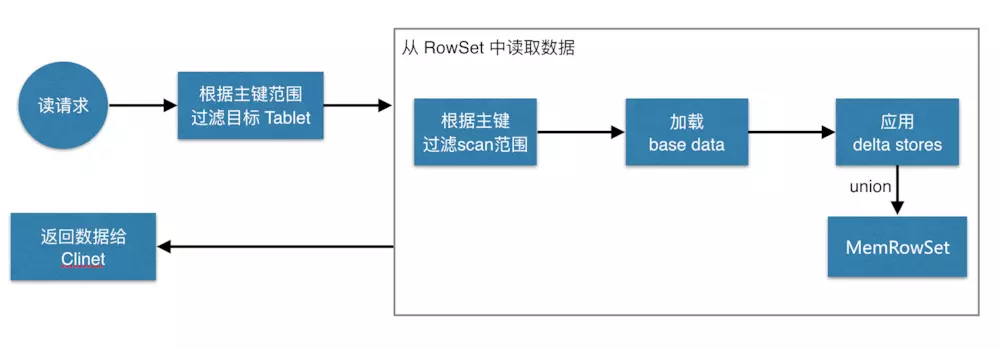
数据读取过程大致如下:先根据要扫描数据的主键范围,定位到目标的Tablets,然后读取Tablets 中的RowSets。
在读取每个RowSet时,先根据主键过滤要scan范围,然后加载范围内的base data,再找到对应的delta stores,应用所有变更,最后union上MemRowSet中的内容,返回数据给Client。
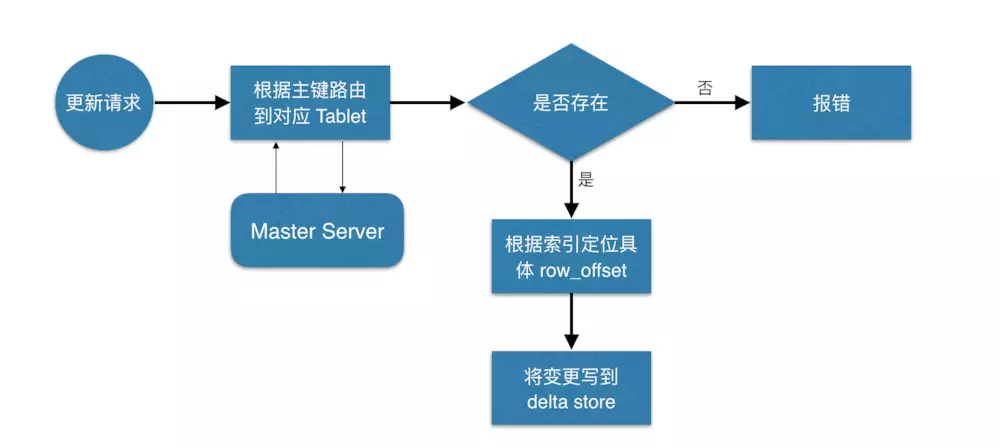
6kudu更新流程
数据更新的核心是定位到待更新数据的位置,这块与写入的时候类似,就不展开了,等定位到具体位置后,然后将变更写到对应的delta store 中。
Ursprünglicher Autor: hechao
Ursprünglicher Link: http://yoursite.com/2018/01/08/kudu/
Copyright-Erklärung: Bitte geben Sie die Quelle des Nachdrucks an.