离线处理与实时处理
离线处理方面Hadoop提供了很好的解决方案,但是针对海量数据的实时处理却一直没有比较好的解决方案
1.1 实现实时计算系统需要解决那些问题
如果让我们自己设计一个实时计算系统,我们要解决哪些问题。
(1)低延迟:都说了是实时计算系统了,延迟是一定要低的。
(2)高性能:性能不高就是浪费机器,浪费机器是要受批评的哦。
(3)分布式:系统都是为应用场景而生的,如果你的应用场景、你的数据和计算单机就能搞定,那么不用考虑这些复杂的问题了。我们所说的是单机搞不定的情况。
(4)可扩展:伴随着业务的发展,我们的数据量、计算量可能会越来越大,所以希望这个系统是可扩展的。
(5)容错:这是分布式系统中通用问题。一个节点挂了不能影响我的应用。
(6)通信:设计的系统需要应用程序开发人员考虑各个处理组件的分布、消息的传递吗?如果是,发人员可能会用不好,也不会想去用。
(7)消息不丢失:用户发布的一个宝贝消息不能在实时处理的时候给丢了,对吧?
1.1 离线计算是什么
离线计算:批量获取数据、批量传输数据、周期性批量计算数据、数据展示
代表技术:Sqoop批量导入数据、HDFS批量存储数据、MapReduce批量计算数据、Hive批量计算数据、***任务调度
日常业务:
1,hivesql
2、调度平台
3、Hadoop集群运维
4、数据清洗(脚本语言)
5、元数据管理
6、数据稽查
7、数据仓库模型架构
流式计算是什么
流式计算:数据实时产生、数据实时传输、数据实时计算、实时展示
代表技术:Flume实时获取数据、Kafka/metaq实时数据存储、Storm/JStorm实时数据计算、Redis实时结果缓存、持久化存储(mysql)。
一句话总结:将源源不断产生的数据实时收集并实时计算,尽可能快的得到计算结果,用来支持决策。
离线计算与实时计算的区别
最大的区别:实时收集、实时计算、实时展示
离线计算,一次计算很多条数据
实时计算,数据被一条一条的计算
一概述
Apache Strom 流式计算框架
Hadoop处理数据时效性不够,Strom能够尽快得到处理后的数据
Strom只负责数据计算,不负责数据存储
一般是kafka的消费者 然后把数据存入Redis
用处
1日志分析,从海量日志中分析出特定的数据,并将分析的结果存入外部存储器用来辅佐决策。
2管道系统, 将一个数据从一个系统传输到另外一个系统, 比如将数据库同步到Hadoop
3消息转化器, 将接受到的消息按照某种格式进行转化,存储到另外一个系统如消息中间件
4统计分析器, 从日志或消息中,提炼出某个字段,然后做count或sum计算,最后将统计值存入外部存储器。中间处理过程可能更复杂。
二 架构
1主从架构
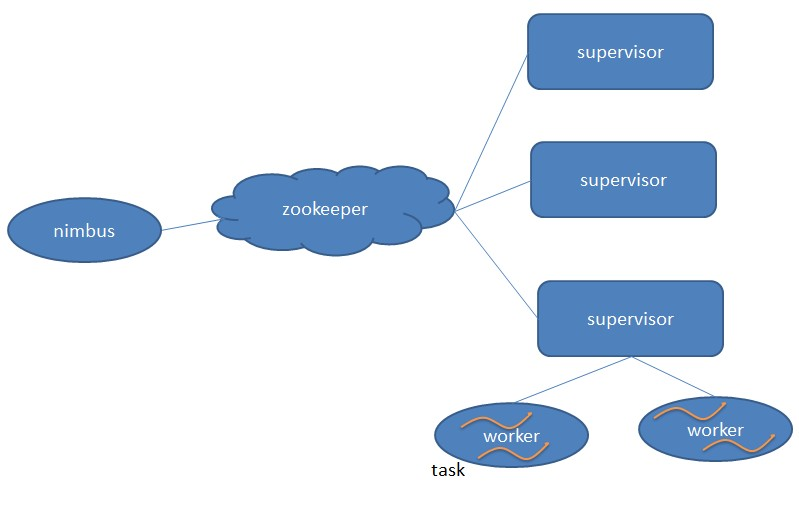
Nimbus:负责资源分配和任务调度。
Supervisor:负责接受nimbus分配的任务,启动和停止属于自己管理的worker进程。
Worker:运行具体处理组件逻辑的进程。
Task:worker中每一个spout/bolt的线程称为一个task. 在storm0.8之后,task不再与物理线程对应,同一个spout/bolt的task可能会共享一个物理线程,该线程称为executor。
2编程模型
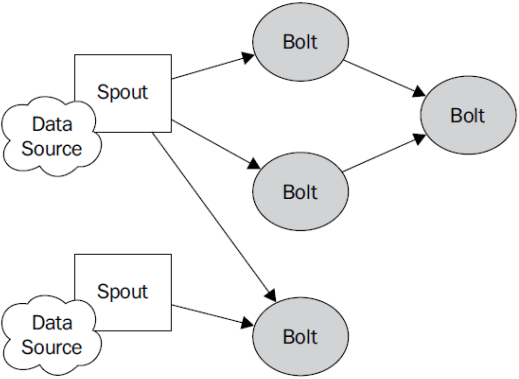
Topology:Storm中运行的一个实时应用程序,因为各个组件间的消息流动形成逻辑上的一个拓扑结构。
Spout:在一个topology中产生源数据流的组件。通常情况下spout会从外部数据源(kafaka)中读取数据,然后转换为topology内部的源数据。Spout是一个主动的角色,其接口中有个nextTuple()函数,storm框架会不停地调用此函数,用户只要在其中生成源数据即可。
Bolt:在一个topology中接受数据然后执行处理的组件。Bolt可以执行过滤、函数操作、合并、写数据库等任何操作。Bolt是一个被动的角色,其接口中有个execute(Tuple input)函数,在接受到消息后会调用此函数,用户可以在其中执行自己想要的操作。
Tuple:一次消息传递的基本单元。本来应该是一个key-value的map,但是由于各个组件间传递的tuple的字段名称已经事先定义好,所以tuple中只要按序填入各个value就行了,所以就是一个value list.
Stream:源源不断传递的tuple就组成了stream。
3分组策略
Stream grouping:即消息的partition方法。
Stream Grouping定义了一个流在Bolt任务间该如何被切分。这里有Storm提供的6个Stream Grouping类型:
\1. 随机分组(Shuffle grouping):随机分发tuple到Bolt的任务,保证每个任务获得相等数量的tuple。 跨服务器通信,浪费网络资源,尽量不适用
\2. 字段分组(Fields grouping):根据指定字段分割数据流,并分组。例如,根据“user-id”字段,相同“user-id”的元组总是分发到同一个任务,不同“user-id”的元组可能分发到不同的任务。 跨服务器,除非有必要,才使用这种方式。
\3. 全部分组(All grouping):tuple被复制到bolt的所有任务。这种类型需要谨慎使用。 人手一份,完全不必要
\4. 全局分组(Global grouping):全部流都分配到bolt的同一个任务。明确地说,是分配给ID最小的那个task。 欺负新人
\5. 无分组(None grouping):你不需要关心流是如何分组。目前,无分组等效于随机分组。但最终,Storm将把无分组的Bolts放到Bolts或Spouts订阅它们的同一线程去执行(如果可能)。
\6. 直接分组(Direct grouping):这是一个特别的分组类型。元组生产者决定tuple由哪个元组处理者任务接收。 点名分配 AckerBolt 消息容错
7.LocalOrShuffle 分组。 优先将数据发送到本地的Task,节约网络通信的资源。
使用storm 进行计算
需求:
单词统计
依赖
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| <dependencies>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<!-- apache storm 1.x | 2.x jstorm和storm合并版本-->
<version>1.1.1</version>
<!-- 目前<scope>可以使用5个值:
* compile,缺省值,适用于所有阶段,会随着项目一起发布。
* provided,类似compile,期望JDK、容器或使用者会提供这个依赖。如servlet.jar。
* runtime,只在运行时使用,如JDBC驱动,适用运行和测试阶段。
* test,只在测试时使用,用于编译和运行测试代码。不会随项目发布。
* system,类似provided,需要显式提供包含依赖的jar,Maven不会在Repository中查找它。 -->
<!--<scope>provided</scope>-->
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.7.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
|
驱动类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.StormSubmitter;
import org.apache.storm.generated.AlreadyAliveException;
import org.apache.storm.generated.AuthorizationException;
import org.apache.storm.generated.InvalidTopologyException;
import org.apache.storm.topology.TopologyBuilder;
/**
* wordcount的驱动类,用来提交任务的。
*/
public class WordCountTopology {
public static void main(String[] args) throws InvalidTopologyException, AuthorizationException, AlreadyAliveException {
// 通过TopologyBuilder来封装任务信息
TopologyBuilder topologyBuilder = new TopologyBuilder();
// 设置spout,获取数据
topologyBuilder.setSpout("readfilespout",new ReadFileSpout(),2);
// 设置splitbolt,对句子进行切割
topologyBuilder.setBolt("splitbolt",new SplitBolt(),4).shuffleGrouping("readfilespout");
// 设置wordcountbolt,对单词进行统计
topologyBuilder.setBolt("wordcountBolt",new WordCountBolt(),2).shuffleGrouping("splitbolt");
// 准备一个配置文件
Config config = new Config();
// storm中任务提交有两种方式,一种方式是本地模式,另一种是集群模式。
// LocalCluster localCluster = new LocalCluster();
// localCluster.submitTopology("wordcount",config,topologyBuilder.createTopology());
//在storm集群中,worker是用来分配的资源。如果一个程序没有指定worker数,那么就会使用默认值。
config.setNumWorkers(2);
//提交到集群
StormSubmitter.submitTopology("wordcount1",config,topologyBuilder.createTopology());
}
}
|
读取文件Spout
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
| import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichSpout;
import org.apache.storm.tuple.Fields;
import java.io.*;
import java.util.Arrays;
import java.util.Map;
/**
* 读取外部的文件,将一行一行的数据发送给下游的bolt
* 类似于hadoop MapReduce中的inputformat
*/
public class ReadFileSpout extends BaseRichSpout {
private SpoutOutputCollector collector;
private BufferedReader bufferedReader;
/**
* 初始化方法,类似于这个类的构造器,只被运行一次
* 一般用来打开数据连接,打开网络连接。
*
* @param conf 传入的是storm集群的配置文件和用户自定义配置文件,一般不用。
* @param context 上下文对象,一般不用
* @param collector 数据输出的收集器,spout类将数据发送给collector,由collector发送给storm框架。
*/
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
try {
bufferedReader = new BufferedReader(new FileReader(new File("//data//wordcount.txt")));
} catch (FileNotFoundException e) {
e.printStackTrace();
}
this.collector = collector;
}
/**
* 下一个tuple,tuple是数据传送的基本单位。
* 后台有个while循环一直调用该方法,每调用一次,就发送一个tuple出去
*/
public void nextTuple() {
String line = null;
try {
line = bufferedReader.readLine();
if (line!=null){
collector.emit(Arrays.asList(line));
}
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 声明发出的数据是什么
*
* @param declarer
*/
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("juzi"));
}
}
|
SplitBolt
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
| import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import java.util.Arrays;
import java.util.HashSet;
import java.util.Map;
/**
* 输入:一行数据
* 计算:对一行数据进行切割
* 输出:单词及单词出现的次数
*/
public class SplitBolt extends BaseRichBolt{
private OutputCollector collector;
/**
* 初始化方法,只被运行一次。
* @param stormConf 配置文件
* @param context 上下文对象,一般不用
* @param collector 数据收集器
*/
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
/**
* 执行业务逻辑的方法
* @param input 获取上游的数据
*/
@Override
public void execute(Tuple input) {
// 获取上游的句子
String juzi = input.getStringByField("juzi");
// 对句子进行切割
String[] words = juzi.split(" ");
// 发送数据
for (String word : words) {
// 需要发送单词及单词出现的次数,共两个字段
collector.emit(Arrays.asList(word,"1"));
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word","num"));
}
}
|
wordcountBolt
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
| import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.tuple.Tuple;
import java.util.HashMap;
import java.util.Map;
/**
* 输入:单词及单词出现的次数
* 输出:打印在控制台
* 负责统计每个单词出现的次数
* 类似于hadoop MapReduce中的reduce函数
*/
public class WordCountBolt extends BaseRichBolt {
private Map<String, Integer> wordCountMap = new HashMap<String, Integer>();
/**
* 初始化方法
*
* @param stormConf 集群及用户自定义的配置文件
* @param context 上下文对象
* @param collector 数据收集器
*/
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
// 由于wordcount是最后一个bolt,所有不需要自定义OutputCollector collector,并赋值。
}
@Override
public void execute(Tuple input) {
//获取单词出现的信息(单词、次数)
String word = input.getStringByField("word");
String num = input.getStringByField("num");
// 定义map记录单词出现的次数
// 开始计数
if (wordCountMap.containsKey(word)) {
Integer integer = wordCountMap.get(word);
wordCountMap.put(word, integer + Integer.parseInt(num));
} else {
wordCountMap.put(word, Integer.parseInt(num));
}
// 打印整个map
System.out.println(wordCountMap);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
// 不发送数据,所以不用实现。
}
}
|
结果分析
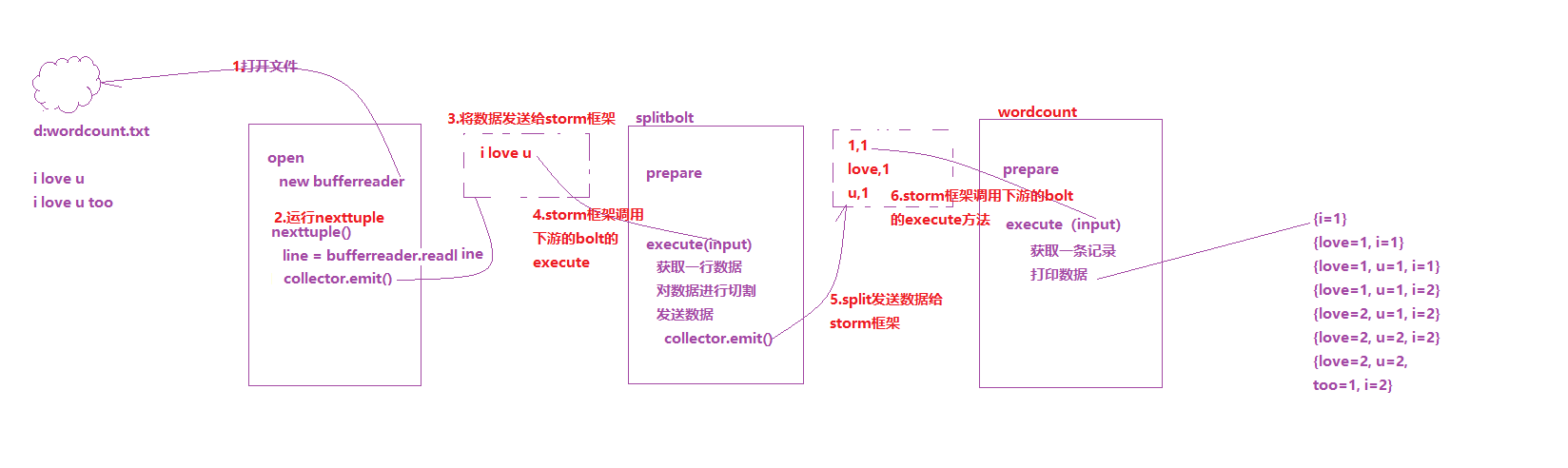
三 集群安装
1上传解压
修改配置文件
1
2
3
4
5
| vim /etc/hosts
192.168.140.128 node01 zk01 kafka01 storm01
192.168.140.129 node02 zk02 kafka02 storm02
192.168.140.130 node03 zk03 kafka03 storm03 mysql
|
修改 storm文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| cd storm/conf
rm storm.yaml
vim storm.yaml
storm.zookeeper.servers:
- "zk01"
- "zk02"
- "zk03"
nimbus.seeds: ["storm01", "storm02", "storm03"]
storm.local.dir: "/export/data/storm"
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
然后把这个storm 发给其他节点
|
启动:
1
2
3
4
| 后台启动 cd bin
主节点 nohup ./storm nimbus &
其他节点 nohup ./storm supervisor &
然后主节点 启动UI nohup ./storm ui &
|
把以上代码提交到集群运行
修改代码
1
2
| 在驱动类中 修改提交方式是提交的集群
在读取文件的勒种 修改文件位置为集群上的
|
运行
1
| storm jar jar包名 驱动类名(包韩路径信息)
|
Ursprünglicher Autor: hechao
Ursprünglicher Link: http://yoursite.com/2017/06/24/Storm/
Copyright-Erklärung: Bitte geben Sie die Quelle des Nachdrucks an.